
Barbarians Lie at the Gates of Automation
Examining innovation in the financial services sector with blind spots primed for increased fraudulent activity
In recent years, we’ve seen substantial traction from Fintech startups disrupting the legacy financial services industry aiming to provide a better customer experience or improve access to financial products/services. And for good reason, financial services is ripe with revenue opportunities. In the US alone, finance and insurance represented 7% ($1.5 trillion) of US GDP in 2018. Venture investment in the category has rapidly accelerated and shows no signs of slowing with global VC investment in Fintech exceeding +$53 billion in 2019.
VC enthusiasm in the category has largely been driven by startups that are a) building the modern cloud banking infrastructure and/or b) offering fresh digital banking experiences offering attractive features to consumers that have historically been neglected. As a result, challenger banking startups are gaining non-trivial market share relative to legacy bank incumbents based on compelling customer experiences and the ability to build/layer features more nimbly than their legacy peers – traditional banks have taken notice.

Automation is so hot right now…
Automation means many things in various technology verticals, but in financial services/insurance categories we’ve seen a rush towards tools that streamline highly manual and repetitive processes using programmed or customizable workflows to accelerate volume and accuracy. Previously, the process of applying for a mortgage included a visit to a lender’s office, an in-person meeting with a mortgage broker outlining the details of one’s financial position, and finally a requested list of documents required to complete an underwriting process for approval. Once these documents were submitted, the underwriter manually typed the details into their system (hopefully they didn’t fudge a zero in the wrong direction) to process and reach a decision on an approval amount.
Thankfully workflow/banking infrastructure companies, like Blend and Unqork, have emerged to offer a seamless white-labeled underwriting experience for banks and newcomers in the financial category to automate previously manual processes. Rather than building a digital mortgage application experience from scratch, many startup and traditional lenders have opted to license software from companies like Blend allowing for a modular setup and integration experience with third-party data sources. The customer kicks off a digital application by entering basic personal and financial information. Customers may then be asked to link existing bank accounts or upload statements to provide evidence of income/assets. Integrators, like Plaid, are then able to connect to a customer’s bank and pull account information to satisfy lender requirements seeking to verify account balances or other relevant data points.
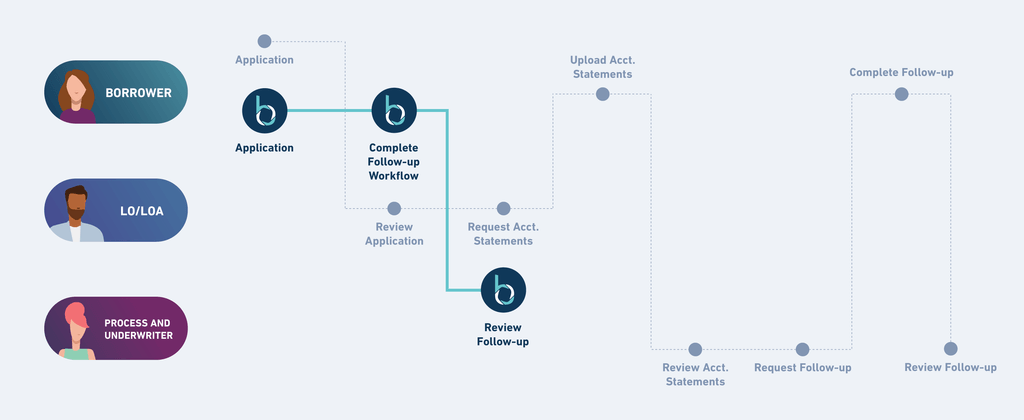
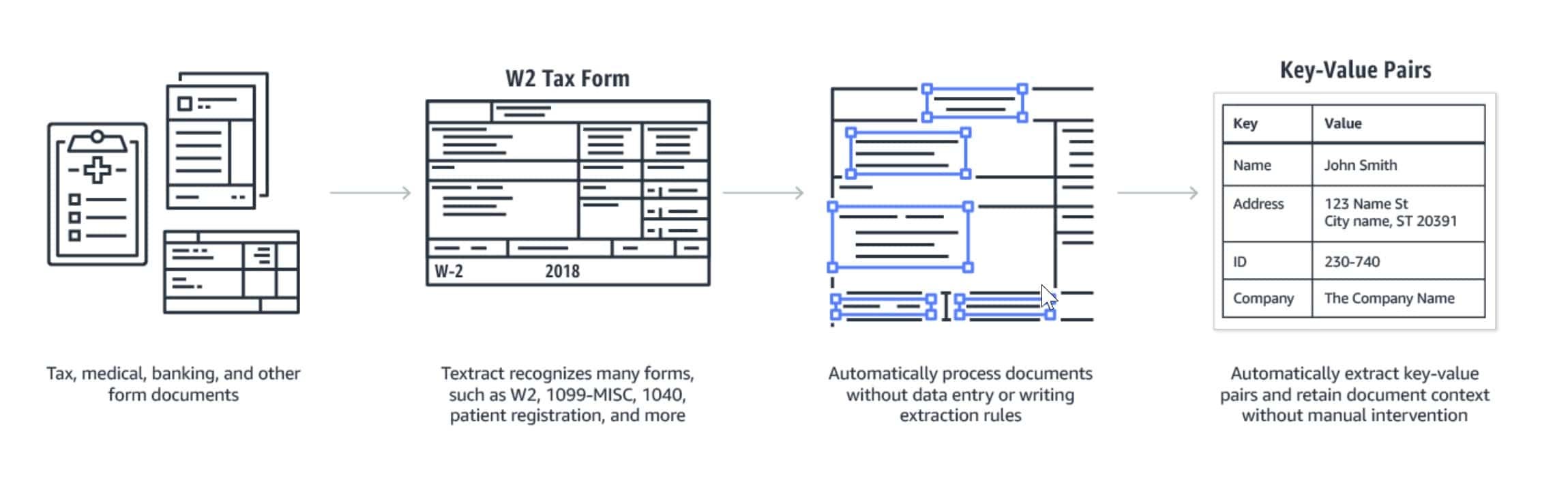
The next step of the application process (requirements typically vary bank-to-bank or based on the type of credit offering requested) is to verify the customer’s financial situation further. This includes uploading a driver’s license, proof of employment via a paystub, or other pertinent statements for further verification. Once uploaded, software analyzes and extracts key data points like Social Security Number, Annual Gross Income, etc. The software used relies on a combination of a) Optical Character Recognition (“OCR”) that recognizes characters and parses into their digital equivalents and b) an ensemble of machine learning algorithms that are trained on example documents to identify the difference between a Social Security and Phone Number, regardless of where it might appear on the document.
OCR extraction technology was previously plagued with inconsistencies if document types varied or Social Security Numbers appeared on different parts of the page from document to document. We’ve seen a strong progression in accuracy of OCR vendors in recent years. There are a variety of approaches but many of the most successful have focused on either delivering depth in specific industries/use cases (higher accuracy/latency for common document types - Ocrolus, Hyperscience) or breadth across many industries/use cases (documents that significantly vary in format - Instabase). Once the relevant data is translated accurately, it can progress to downstream workflows to underwrite and approve customers for a variety of services.
Example of OCR extraction:
Automation with a side of fraud…
There’s a critical gap in existing document verification workflows and fraudsters are salivating. Banks take great care to catch potential fraud at every corner and digitizing data without checks merely pushes fraud/manipulation further upstream where fraudsters can forge documents before uploading, steal/replace Social Security Numbers on legitimate documents, or use other malicious behavior to trick automated pipelines into deeming these applications as “safe” / “approved”.
As I mentioned earlier, data extraction vendors rely on a sophisticated combination of machine learning algorithms and training data sets to optimize for the highest rates of accuracy and latency. But I’ve yet to see these vendors leverage an adversarial approach to analyze the legitimacy of documents being verified. Automated pipelines need checks in place to ensure data inputs are “accurate” but also confirmed “safe and free of fraud”.
Resistant.ai and Inscribe.ai are two promising early-stage startups which leverage forensic analysis and other sophisticated techniques to highlight problematic documents, providing root cause analysis where document forgery or manipulation may exist for further verification. Similar to the progression in OCR technology, I expect these vendors to start with the most common types of documents and progress more broadly to examine the long tail of documents over time.
One particular tailwind to this segment of document verification in an increasingly uncertain economic environment is a potential shift away from lenders historically relying on credit bureau data to incorporate additional documentation verifying current employment/income. I suspect an increasing proportion of fraud will emerge in this area.
As Mark Twain says…
As the popular saying goes: “history never repeats itself, but it rhymes”. So does fraud. Fraudsters are creative and continue to identify areas of weakness before driving a truck through the perimeter. I’m interested to see other areas of innovation where startups are working to strengthen these blind spots.
While I view financial services as a beachhead for fraud detection use cases, there are certainly many applications in other industries such as healthcare reimbursement, corporate expense/tax reporting, etc.
Oh, and IRS audits might be quite the thrill in future years.
Views are my own and do not represent my employer. You can reach me at stewart.pond [at] capitalone.com or follow me on Twitter
Would love to hear your thoughts - agree or disagree or feel free to share w/ your friends!